
腾讯云轻量应用服务器部署halo
准备 mkdir -p /export/server mkdir -p /export/software 安装mysql rpm -qa|grep mariadb rpm -e mariadb-connector-c-3.1.11-2.oc8.1.x86_64 --nodeps rpm -e mar

十万大山起于尘埃——起微山重装
十万大山起于尘埃——起微山重装 前言 之前在看《诛仙》的啥时候就对于里面的苗疆十万大山的神秘感相当的感兴趣,后面随着行走的地方越来越多之后,知道小说中的十万大山确实在现实中有真实依据的,就是参照横贯湘西、粤北的绵延山脉,既然山就在哪里,那么有必要去看看这传说中的十万大山的真面目。 这次其实是我第一次

第一次在海边露营
第一次在海边露营 缘起 最近进了阅路山的华南地区群,感觉一下回到故乡,大家都是讨论着去哪里徒步,看了群友的分享,会发现每天都是不想上班的一天,不过也有很多劝退的各种装备分享,大说很好很好,一看价格发现我不太配徒步。 这个群上周才建立,然后就有各种深圳约着去露营和徒步的,本来我是打算去武功山徒步两天,

时代是钢铁的,而个人是块豆腐——《四世同堂》读后感
前言 总算是看完了这本书,太长了,完全可以媲美甚至超越了巴金的《家春秋》,路遥的《平凡的世界》,还有大刘的《三体》。 而这几部长篇小说其实都是中华民族的史诗,《家春秋》描绘了中华民族从封建社会开始逐渐地瓦解下的一个大家族走向分化与衰落,接着就是《四世同堂》下的从抗日战争爆发到最终结束中的一个北京小家

HiveSQL执行计划
查看SQL的执行计划 Hive提供的执行计划目前可以查看的信息有以下几种: 查看执行计划的基本信息,即explain; 查看执行计划的扩展信息,即explain extended; 查看SQL数据输入依赖的信息,即explain dependency; 查看SQL操作相关权限的信息,即explain

Hive性能优化-原则与规范
Hive性能优化-原则与规范 从一个过度调优案例说起 下面有一个关于去重计数的代码,可以看看两种不同的去重方式 -- 第一种 select count(1) from ( select s_age from student_tb_orc group by a_age ) b --
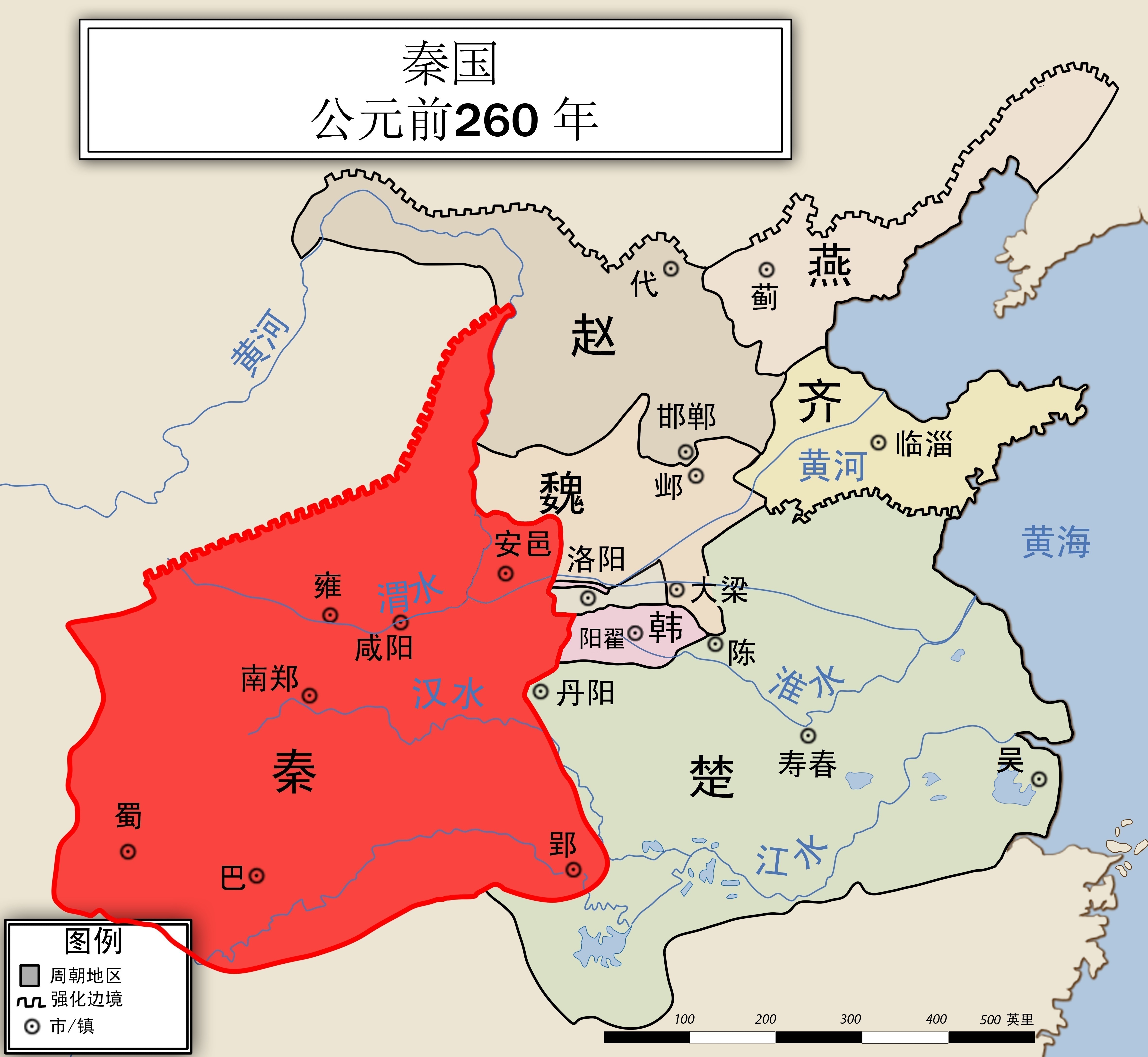
秦隋虽短,历史功劳不亚汉唐
最近看了温铁军:秦灭亡是因为暴政?中国不该形成大一统?身处西方话语体系会让你忘了自己的根还有一名历史UP主安州牧解读的《风云南北朝》系列,再加上对比之前自己看过的《奥斯曼帝国六百年:土耳其帝国的兴衰》、《奥斯曼帝国:五百年的和平》、《印度通史》,还有播客节目《中东往事》。 比较认可温老师的观点,虽然

深入了解MapReduce计算引擎及Hive相关优化
MapReduce整体处理过程 MapReduce运行所需要经过的环节 进一步分解为: MapReduce作业输入 作业输入的核心是InputFormat类,用于MapReduce作业的输入规范,读取数据文件的规范。 输入格式类InputFormat InputFormat涉及3个接口/类,即Inp

Hive及其相关的大数据组件
Hive架构 YARN和Hive的协作关系 客户端提交SQL作业到HiveServer2,HiveServer2会根据用户提交的SQL作业及数据库中现有的元数据信息生成一份可供计算引擎执行的计划。每个执行计划对应若干MapReduce作业,Hive会将所有的MapReduce作业都一一提交到YARN

成功登顶四姑娘山二峰回顾
历经五天的清明小假,完成了冲顶5000+山顶的心愿。虽然只有短短的五天时间,但是却是异常的充实,抓住这几天时间,即把把自己心心念念的三星堆博物馆逛了,也去看了最近国内各处的顶流——大熊猫(虽然没能看到其中顶顶流女明星——花花)。 我们这次去登雪山,我基本上是提前一个月就开始着手准备,无论是身体上的体